プログラミング言語Idris自体についての詳しい話はここではしない。このブログの昔の記事で軽く紹介したかもしれないが他人の参考になるかは分からない。
この記事を読むにあたっては、
- ペアノ算術
は知ってないと厳しいと思われる。あとHaskell風の言語にも慣れていた方がいいか。
この記事で使うIdrisのバージョンは0.9.16である(執筆時点の最新版)。これと異なるバージョンだとコードの修正が必要かもしれない。

【2017年12月18日 追記】この記事は古いTypeScript (2.0以前) を念頭に置いている。もちろん、現在のTypeScriptにも当てはまる記事はあるだろうし、TypeScript以外の言語における合併型 (union types) についてもある程度読み替えられるかもしれない。ただしElmとは “Union Types” の用法が完全に相入れないのでElmユーザーの方はお帰りください。
TypeScript 1.4について、 TypeScript 1.4.1 変更点 – Qiita という記事が目に留まった。で、その中の
直和型(Union Types)
という項目に引っかかりを感じた。:
なぜ引っかかりを感じたかというと、TypeScriptに今回導入されたUnion Typesと、巷に言う直和型というのは、異なる概念であるからだ。
注意:以下の話は型理論の専門家でもないフツーの学生が適当に書いた程度の信憑性しかありません。
TypeScript 1.4がリリースされた。目玉機能としては Union Types とか ECMAScript 6 出力モードの搭載とかになるのだろうが、他にもいろいろ地味だが嬉しい機能追加などがあるようだった。
前にTypeScriptで組み込みオブジェクトを拡張できないというようなことを書いたが、そのとき感じた問題点が直っている。具体的には以下。
interface ほにゃららConstructor というものに変更されている。よって、各種組み込みオブジェクトのコンストラクタに勝手なプロパティーを追加できる。あと地味に便利だと思ったのはコンパイラ tsc に追加された --noEmitOnError というオプションである。今まではソースコードが解釈さえできれば型チェックが通らなくても ECMAScript の出力が生成(!)されていて、Makefile で TypeScript のコードをコンパイルする時に不便だった。だが、このオプションがあれば型チェックが通ったコードしか出力されないので、Makefile との相性が上がる。
SVGとはScalable Vector Graphicsの略で、2次元のベクター画像を記述するためのXMLベースの言語である。詳しくはググれ。
ベクター画像を構成する要素は、線分とか円とかベジエ曲線とかいろいろある。SVGでこれをどう表すかというと、例えば線分だとline要素を使い、円だとcircle要素を使う。SVGにはこの他にpath要素というものがあって、描画のコマンドを文字列で指定して複雑な曲線を描ける。線分とか円の弧のような単純なやつも描ける。
例を見てみると、
M 100 100 L 300 100 L 200 300 z
というコマンドを与えると、始点(100,100)から(300,100)に線分を描き、そこから続けて(200,300)に線分を描く。最後に、(200,300)から始点に線分を描いてパスを閉じる。この M とか L とか z とかいうのが描画コマンドで、それぞれ move to, line to, close path を意味する。2次元の描画を行うプログラムの経験がある人にはおなじみだろう。
描画コマンドには他にも2次あるいは3次のベジエ曲線を描くもの、楕円の弧を描くものがある。この楕円の弧を描くコマンド(A / a)が曲者で、楕円の指定方法が個性的だった。
このコマンドに与えるパラメーターは、楕円の形状に関する物が3つ、弧の終点(始点は current point を使うので、わざわざ指定する必要はない。指定したい場合は先に move to コマンドを実行する。)、そして、弧の端点と楕円の位置関係を指定するフラグが2つだ。楕円の中心は明示的に指定できない。
フラグが2つもある時点で嫌な予感がする。場合分けとか面倒くさそう。そんなことを感じながら、自前のSVGを出力するライブラリ(と言ったら大げさか)を実装・バグ取りしていたが、なぜか円全体が描けない。おかしい。と思ったが気が付いた。
始点と終点が一致していると、楕円の中心が一意に定まらない。つまり、SVG pathの A コマンドでは1回で楕円を描けない。SVGの楕円に類する物を描く描画コマンドは他にないのに…。
ググってみたら、Stack Overflowの質問を見つけた。
Circle drawing with SVG’s arc path – Stack Overflow
要するに、SVG pathで楕円全体を描くには、楕円の99.99%の弧を描いて満足するか、2個のコマンドで楕円を分割して描かないといけない。腐った仕様だ。
ちなみに、PostScriptの仕様をちらっと見た感じでは、PostScriptで円弧を描く arc コマンドは円の中心と半径、始点と終点の角度を指定する仕様だった。HTML5 Canvasの2D Contextも同様だ。(これらには楕円を描くコマンドはないが)
フリーのペイントソフト、GIMPをゲームパッドで操作したい。いわゆる「左手デバイス」とかいうの。まあ自分はそんなにお絵描きするわけじゃないんだけど。
ここの話はLinuxでの話で、WindowsとかOS Xとかは知らん。

1. メニューの「Edit > Preferences」を選択。
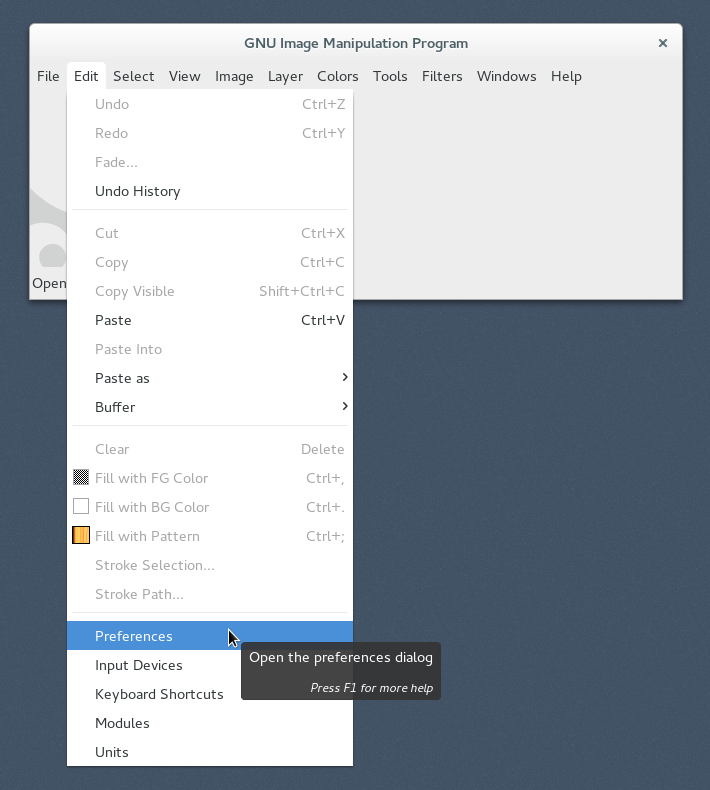
2. Preferences ダイアログの Input Devices > Input Controllers を選択
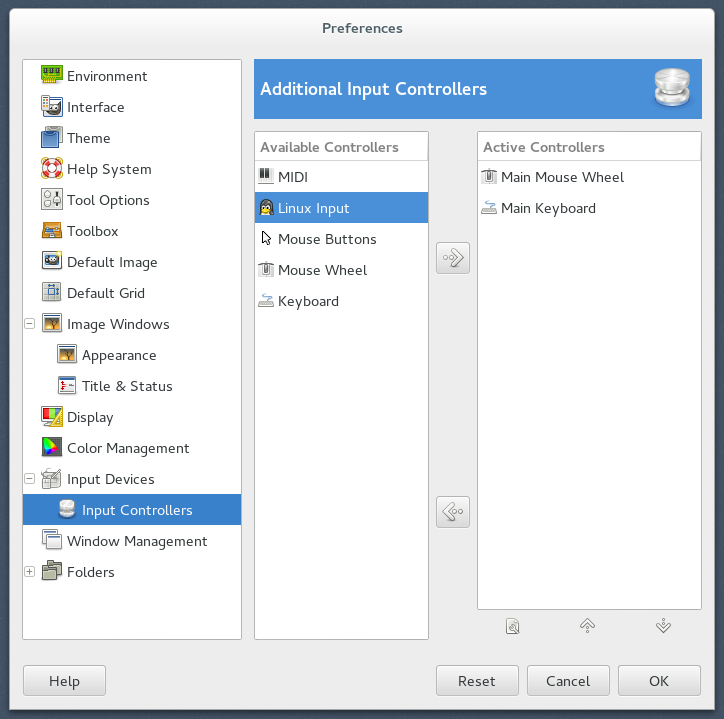
3. Available Controllers の Linux Input を選択し、→ボタンで Active Controllers に追加。
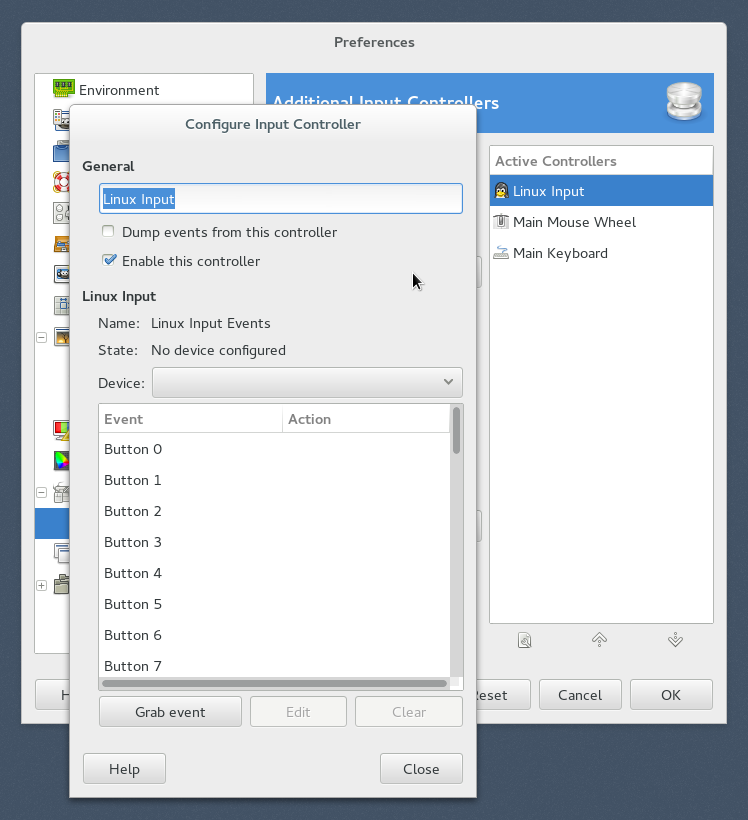
4. Configure Input Controller ダイアログが出てくるので、Deviceとして PC Game Controller を選択。
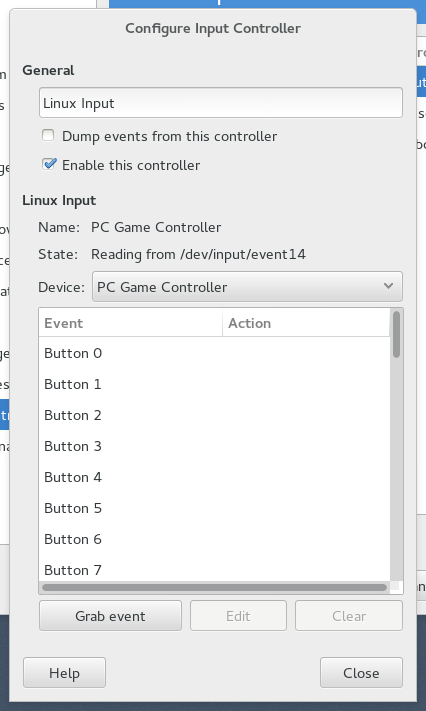 これで、
これで、
という感じでゲームパッドのボタンにGIMPの操作を割り当てることができる…と期待したがそうはいかなかった。ゲームパッドのボタンを押しても何も起こらない。Dump events…にチェックを入れてターミナルの出力を見ると、ボタンを押した事自体は認識されてはいるようだ。なぜだ。
しかたがないからGIMPのソースコードを見ていじくろう。GIMP Developer WikiのHacking:Building/Linuxを参考にして、ソースコードをgitでチェックアウトする。
Linux Inputに対応するソースはどこだろう。gimp/modules/ が怪しい。見てみると、gimp/modules/controller-linux-input.c というソースファイルがある。これか。
ファイルの頭の方に static const LinuxInputEvent key_events[] という変数の定義がある。Configure Input Controllerダイアログに出てきたボタンの名前はこれか。ゲームパッドのキーを押したときにターミナルに出てくるログと、<linux/input.h> で定義されている定数の値を参考にしながら、BTN_*** に対応する定義を追加する。
差分としてはこんな感じになった。
diff --git a/modules/controller-linux-input.c b/modules/controller-linux-input.c
index 8759d10..de72332 100644
--- a/modules/controller-linux-input.c
+++ b/modules/controller-linux-input.c
@@ -81,8 +81,20 @@ static const LinuxInputEvent key_events[] =
{ BTN_GEAR_DOWN, "button-gear-down", N_("Button Gear Down") },
#endif
#ifdef BTN_GEAR_UP
- { BTN_GEAR_UP, "button-gear-up", N_("Button Gear Up") }
+ { BTN_GEAR_UP, "button-gear-up", N_("Button Gear Up") },
#endif
+ { BTN_TRIGGER, "button-trigger", N_("Button Trigger") },
+ { BTN_THUMB, "button-thumb", N_("Button Thumb") },
+ { BTN_THUMB2, "button-thumb2", N_("Button Thumb 2") },
+ { BTN_TOP, "button-top", N_("Button Top") },
+ { BTN_TOP2, "button-top2", N_("Button Top 2") },
+ { BTN_PINKIE, "button-pinkie", N_("Button Pinkie") },
+ { BTN_BASE, "button-base", N_("Button Base") },
+ { BTN_BASE2, "button-base2", N_("Button Base 2") },
+ { BTN_BASE3, "button-base3", N_("Button Base 3") },
+ { BTN_BASE4, "button-base4", N_("Button Base 4") },
+ { BTN_BASE5, "button-base5", N_("Button Base 5") },
+ { BTN_BASE6, "button-base6", N_("Button Base 6") },
};
static const LinuxInputEvent rel_events[] =
あとは、さっきのWikiの手順にしたがってGIMPをビルドする。すると、さっきスクリーンショット付きで説明した手順で、ゲームパッドのボタンにGIMPの操作を割り当てることができる。
とりあえず気づいた点は、ボタンを押すときと離すときで2回操作が実行されるのと、ゲームパッドのボタンじゃなくて倒すやつには反応しないこと。既存のソースコードの見よう見まねじゃなくて、ちゃんと調べてコードを書かないといけない気がする。そもそもこのLinux Inputというやつはどのぐらい使われているんだろうか。これは意図した動作なのだろうか。
あと、自分の手持ちのゲームパッド1個で試したが、他のゲームパッドではどうなるのか。この辺の問題が解決したらパッチを投げるかもしれない。その前に開発コミュニティーの雰囲気とかつかんでおきたいが。パッチを投稿するにはBugzillaにBug(?)を登録してそれに添付する感じだろうか。この辺の手間を思うに、GitHubのPull Requestという仕組みは偉大だ。
ペンタブのパッド(ペンタブの感知するエリアの横についてるボタン)に対する操作も、Linux Inputで扱えそうな雰囲気を感じたが、Wacomのドライバと競合するのか知らないがなにかうまくいかない。
Cabalを使ってHaskellのパッケージ管理をやっていると、依存関係がもつれて酷い事になる。あるプロジェクトで使うパッケージと別のプロジェクトで使うパッケージが干渉したりとかなんかそういうアレだ。こういう時はsandboxを使うと良いらしい。マニュアル
自分のプロジェクトのディレクトリで
$ cabal sandbox init
を実行すれば、新しいsandboxができる。何かパッケージを入れようと思ったら、そのディレクトリで普通に
$ cabal install ほげほげ
を実行すればそのパッケージはそのディレクトリに入る。
sandbox内のパッケージを使ってghciを起動したい場合は、
$ cabal repl
を使う。
sandbox内のパッケージを使ってghcやrunghcなどのコマンドを叩きたい場合は、1.20.0で追加された(?)execコマンドを使うといいようだ。
$ cabal exec ghc -- --make hogehoge.hs
この記事はcabal-install 1.21.0.0の時点の情報をテキトーに調べた結果を書いたので、もしかしたらもっと正しい使い方とかあるのかもしれないが、そんなもん知らん。
(9月21日: typoを修正)
最近、自分で書くWebアプリ、ブラウザアプリには、JavaScriptの代替言語としてTypeScriptを使っている。
TypeScriptの気に入っている点は、
あたりである。逆に、不満があるとすれば
あたりであろうか。まあ不満があったら他のaltJSを使えばいい話だが。
[2015年1月18日 追記] 以下の内容はTypeScript 1.4のリリースに伴い古くなりました。詳しくはこちら。
ECMAScript 6で導入されるライブラリ関数は、一部は型宣言を書いてやることでTypeScriptからも使えるようになる。例えば、前の記事で Math.hypot や Math.sinh などの関数に触れたが、それらは[sourcecode lang=”js”]
interface Math {
hypot(…values: number[]): number;
sinh(x: number): number;
}
[/sourcecode]のような宣言を書いておけば、コンパイルが通るようになる。まだこれらの関数を実装していないブラウザ用に、polyfill(shim)も書いておくか、読み込むといいだろう。
このほか、例えば、Array.prototype.find の型宣言は[sourcecode lang=”js”]
interface Array<T> {
find(callback: (element: T, index: number, array: T[]) => boolean, thisArg?: any): T;
}
[/sourcecode]というふうにできる。
ここまではいい。
JavaScriptのイディオムとして、配列ライクなオブジェクトを変換するのに、Array.prototype.slice が使われる。もちろんこのイディオムはTypeScriptでも使えるが、Array.prototype の型は Array<any> となっているので、要素の型に対する型チェックや型推論が働いてくれない。幸い、ECMAScript 6では、Array.from という関数が導入される予定なので、こいつの型を[sourcecode lang=”js”]
from<T>(arrayLike: {[n: number]: T; length: number}): T[];
[/sourcecode]のように宣言してやれば型推論とかが効いて便利なはずだ。
だがしかし。組み込みの Array オブジェクトの型は標準の lib.d.ts において[sourcecode lang=”js”]
declare var Array: {
new (arrayLength?: number): any[];
…
prototype: Array<any>;
}
[/sourcecode]のように宣言されている。こいつに from メソッドを追加しようとして自分のコードで[sourcecode lang=”js”]
declare var Array: {
from<T>(arrayLike: {[n: number]: T; length: number}): T[];
}
[/sourcecode]と書くとエラーが出る。既存のメソッドも書かないとダメかと思って[sourcecode lang=”js”]
declare var Array: {
new (arrayLength?: number): any[];
…
prototype: Array<any>;
from<T>(arrayLike: {[n: number]: T; length: number}): T[];
}
[/sourcecode]と書いてもエラーになる。モジュールならばどうかと思って[sourcecode lang=”js”]
module Array {
from<T>(arrayLike: {[n: number]: T; length: number}): T[];
}
[/sourcecode]と書いてもエラーになる。組み込みの Array オブジェクトの型は lib.d.ts で書かれたものから変更できないのだ。
だがちょっと待て。Math オブジェクトは自前で拡張できたではないか。これは何でだったかというと、Math オブジェクトは[sourcecode lang=”js”]
interface Math {
…
}
declare var Math: Math;
[/sourcecode]という風に定義されていて、Math インターフェースにメソッドを追加すれば Math オブジェクトを拡張できたのだ。Array も[sourcecode lang=”js”]
interface ArrayConstructor {
new (arrayLength?: number): any[];
…
prototype: Array<any>;
}
declare var Array: ArrayConstructor;
[/sourcecode]と定義されていれば良かったのに。Array だけではなくて、Object, Number, String 等の組み込みオブジェクトも同じ問題を抱えている。
ググってみたらすでに同じ問題で悩んでいる人がいた。
最初のStack Overflowの回答によると、「自前の lib.d.ts を用意しろ」らしい。つらい。
[2015年1月18日 追記] 以上の問題点はTypeScript 1.4のリリースにより解決しました。詳しくはこちら。
目次
ベジエ曲線とはWikipedia(英語版)によると(本当はちゃんとした文献を当たるべきなのだろうが)、\(n+1\) 個の点 \(x_0, x_1, \dots, x_n\) が与えられた時に\[
B(t)=\sum_{i=0}^{n}\binom{n}{i}t^i(1-t)^{n-i}x_i, \quad 0\le t\le 1
\]で定まる曲線らしい。始点 (\(t=0\)) は \(x_0\)、終点(\(t=1\))は \(x_n\) である。\(n\) のことを次数という。
(1次の場合は単なる線分なので置いておいて)よく使われるのは2次の場合と3次の場合である。それぞれ\begin{align*}
\mathit{quadratic B\acute{e}zier}(t)&=(1-t)^2x_0+2t(1-t)x_1+t^2x_2, \\
\mathit{cubic B\acute{e}zier}(t)&=(1-t)^3x_0+3t(1-t)^2x_1+3t^2(1-t)x_2+t^3x_3
\end{align*}で与えられる。
2次の場合は始点 \(x_0\) と終点 \(x_2\) の他に1個の制御点 \(x_1\)、3次の場合は始点 \(x_0\)、終点 \(x_3\) の他に2個の制御点 \(x_1\), \(x_2\) によって決まる。制御点は始点及び終点における接線を与えるためにある。ここではベジエ曲線についてはこれ以上突っ込んだ事は取り扱わない。
こういう、「制御点を与えて曲線を描く」のは、ドロー系の描画ソフトウエアを使ったことのある方はおなじみだろう。SVGやPostScriptなどのベクター画像形式でも、ベジエ曲線は基本的な描画対象である。
プログラミングに関して言うと、大抵のグラフィックAPIには2次か3次のベジエ曲線を描画するAPIがある。例えば、HTML5 Canvasの場合は
context.quadraticCurveTo(cpx, cpy, x, y) /* 2次 */ context.bezierCurveTo(cp1x, cp1y, cp2x, cp2y, x, y) /* 3次 */
というAPIがあり、Cocoaの場合は
NSBezierPath -(void)curveToPoint:(NSPoint)aPoint controlPoint1:(NSPoint1) controlPoint2:(NSPoint)controlPoint2 /* 3次 */
というAPIがある。いずれも始点を指定する引数がないが、これらのAPIを使った時の始点は「現在の点の位置」になる。つまり、最後の描画操作における終点か、あるいはmoveToなどのAPIを使って指定した点である。
さて、滑らかな曲線 \(f\colon[0,1]\to\mathbf{R}^2\) をベジエ曲線で近似するということを考えよう。動機としては例えば、プログラミングで曲線を描きたい時に、大抵のグラフィックスAPIには任意の曲線を描画するようなAPIはないので(2次か3次の)ベジエ曲線を使って近似する事になる。2次か3次と書いたが、以後3次のベジエ曲線で近似する事を考える。
C言語をはじめとする多くのプログラミング言語には、exp, log, sqrt などの指数、対数、平方根の関数や、 cos, sin, tan などの三角関数、cosh, sinh, tanh などの双曲線関数が備わっている。これらの数学関数はECMAScript (JavaScript)からは、Mathオブジェクト経由で Math.exp や Math.cos などのようにアクセスできる(が、現状ECMAScriptには双曲線関数はない)。
さて、C99でこれらに加えて、acosh, asinh, atanh などの逆双曲線関数や、expm1 や log1p などの「精度を意識した」関数などが追加された(expm1は\(\exp x-1\), log1p は \(\log(1+x)\) を計算する関数である)。これらの関数をECMAScriptで使うにはどうすればいいか?
ECMAScriptの次期標準であるECMAScript 6では、双曲線関数 Math.(cosh|sinh|tanh) や、C99で追加された関数に対応する Math.(acosh|asinh|atanh) や Math.expm1, Math.log1p が入るらしい(Firefoxなどでは既に実装されている)。しかし、ECMAScript 6に非対応の環境では、これらの関数は自前で実装するしかない。
幸い、双曲線関数は指数関数で書ける。よって、例えば Math.sinh はECMAScriptに既に存在する Math.exp 関数を使って次のように書ける:
[sourcecode lang=”js”]
Math.sinh = Math.sinh || function(x) {
return (Math.exp(x)-Math.exp(-x))/2;
};
[/sourcecode]
Mozillaのサイトにも代替コード(Polyfill)として同じようなコードが載っている。めでたしめでたし。
といいたいところだが、精度を気にする場合はそうはいかない。例えば、\(x\) にとても小さい数、例えば \(x=10^{-20}\) を代入してみるとどうなるだろうか。\(\sinh\) のテーラー展開\[
\sinh x=x+\frac{x^3}{3!}+\cdots
\]を考えると(\(x^3\) は微小なので無視して)値はおおよそ \(x=10^{-20}\) と一致するはずである。この場合、ECMAScriptの「数」はIEEE754の64bit浮動小数点数で、精度は53bitしかないため、\(x\) が十分に小さければ \(x+\frac{x^3}{3!}+\dots\) は完全に \(x\) と一致する。
一方、指数関数のテーラー展開は\[
\exp x=1+x+\frac{x^2}{2!}+\cdots
\]で、今書いたのと同じ理由で Math.exp(x) や Math.exp(-x) は完全に 1 と等しくなる。従って、さっき実装したオレオレ Math.sinh は0を返す。情報落ちだか桁落ちだか忘れたが、なんかそういう現象が起こっている。これは理想的とはいえない。ちなみに、C言語の sinh はこの場合「正しい」 \(10^{-20}\) を返す。
同様に、Math.expm1 を次のように愚直に実装しても、同じ問題が発生する。
[sourcecode lang=”js”]
Math.expm1 = Math.expm1 || function(x) {
return Math.exp(x)-1;
};
[/sourcecode]
では、どうすれば \(x\) が小さい時でも「正しい」答えを出す expm1 関数を作れるか?(双曲線関数よりも指数関数の方が単純なので、以後こちらを議論する)
まあ単純な答えとしては、 \(x\) が小さいときに関数のテイラー展開を使って多項式として計算してやれば良い。さっきのように \(x=10^{-20}\) とかだと1次近似で \(x\) そのものを返してやればよかったが、この近似は \(x\) がどのぐらい小さければ問題ないのか?あるいは、近似の次数をどのぐらい増やしてやれば誤差はどれぐらい小さくなるか?
仮に、\(\exp x\) を \(n\) 次の多項式で近似するとしよう。すると、真の値(無限級数で表される)との差は\[
\left\lvert(\text{差})\right\rvert=\left\lvert\exp x-1-\sum_{k=1}^{n}\frac{x^k}{k!}\right\rvert=\left\lvert\sum_{k=n+1}^{\infty}\frac{x^k}{k!}\right\rvert
\]となる。これを適当に評価してやれば良い。実際にやってみると、例えば次のようになる。\begin{align*}
\left\lvert(\text{差})\right\rvert=\left\lvert\sum_{k=n+1}^{\infty}\frac{x^k}{k!}\right\rvert
&\le\sum_{k=n+1}^{\infty}\frac{\lvert x\rvert^k}{k!} \\
&=\frac{\lvert x\rvert^{n+1}}{(n+1)!}\sum_{k=0}^{\infty}\frac{\lvert x\rvert^k}{(n+2)\cdot\dots\cdot(n+k+1)} \\
&\le\frac{\lvert x\rvert^{n+1}}{(n+1)!}\sum_{k=0}^{\infty}\frac{1}{(n+2)^k} \quad (\left\lvert x\right\rvert <1\text{を仮定}) \\
&\le\frac{\left\lvert x\right\rvert^{n+1}}{(n+1)!}\frac{1}{1-\frac{1}{n+2}} \\
&\le\frac{\left\lvert x\right\rvert^{n+1}}{(n+1)!}\frac{n+2}{n+1}=\frac{(n+2)\left\lvert x\right\rvert^{n+1}}{(n+1)(n+1)!}
\end{align*}
では、どういうときに \(n\) 次の多項式近似の値を使ってよいかというと、近似値 \(\sum_{k=1}^{n}\frac{x^k}{k!}\) の大きさに対してこの \(\left\lvert(\text{差})\right\rvert\) の大きさが(精度が53bitの浮動小数点数の場合は) \(2^{-53}\) よりも小さければ確実に問題ない(十分条件)。つまり\begin{align*}
\left\lvert\frac{(\text{差})}{\sum_{k=1}^{n}\frac{x^k}{k!}}\right\rvert<2^{-53}
\end{align*}だ。この左辺をもうちょっと分かりやすい形で評価すると
\begin{align*}
\left\lvert\frac{(\text{差})}{\sum_{k=1}^{n}\frac{x^k}{k!}}\right\rvert&\le\left\lvert\frac{(\text{差})}{x}\right\rvert \\
&=\left\lvert\frac{1}{x}\frac{(n+2)\left\lvert x\right\rvert^{n+1}}{(n+1)(n+1)!}\right\rvert \\
&=\frac{(n+2)\left\lvert x\right\rvert^n}{(n+1)(n+1)!}
\end{align*}
となる(書いた後に気付いたが、最初の行の評価が \(x<0\) のときにマズい気がする)。つまり、\(n\) 次近似を使っても良い十分条件として\[
\frac{(n+2)\left\lvert x\right\rvert^n}{(n+1)(n+1)!}<2^{-53},
\]すなわち\[
\left\lvert x\right\rvert<\sqrt[n]{\frac{(n+1)(n+1)!}{n+2}2^{-53}}
\]が得られる。
例えば、\(n=3\) として右辺を計算すると \(1.286976\ldots\times 10^{-5}\) が得られるので、さっきのオレオレ Math.expm1 の実装は
[sourcecode lang=”js”]
Math.expm1 = Math.expm1 || function(x) {
if (Math.abs(x) <= 1.28e-5) {
return x*(1+x/2*(1+x/3));
} else {
return Math.exp(x)-1;
}
};
[/sourcecode]
のように改良できる。
まあ、改良したと言っても所詮お遊びで、実際のC言語のライブラリの実装はこんな適当なコードよりもちゃんとやっているので、真面目にやりたい人はC言語のライブラリの実装を移植しよう。
Math.expm1 の他に、Math.log1p, Math.sinh, Math.tanh, Math.asinh, Math.atanh あたりの関数を実装する時にも同じような(小手先の)テクニックが使える。
ところで、MDNに載っている Math.tanh のPolyfillに問題があるのを見つけた。MDNのPolyfillでは x が Infinity かどうかを関数の最初でチェックしているが、x が Infinity でなくても Math.exp(x) が Infinity になる場合を考慮していない。その結果、Math.tanh(x) に 1 を返してほしいのに実際には NaN が返ってくる場合がある。
最後に全く関係ない話だが、プログラミング言語Luaは標準ライブラリに math.sinh などの双曲線関数を計算する関数(中ではC言語のライブラリ関数を呼び出す)を持っている。しかし、どうやら将来的にはこれらの双曲線関数を標準ライブラリから外すようだ(次期バージョン5.3でdeprecated扱い)。理由として作者は「あまり使われていない」「必要なら mathx などの外部ライブラリを使えば良い」としている(この記事に書いた理由により、「math.exp で実装できる」は理由にならない)。ECMAScript と Lua はよく似ていると言われる事が多いが、一方がWebの世界のアセンブラとなるべく数学関数・浮動小数点数関係の関数を追加しようとしているのに対し、もう一方はそれを削減しようとしているのは対照的だと思った。(まあ筆者自身はLuaを活発に触っていたのは5.1時代の事で、5.2が出て以降はあまり触っていないので、ぶっちゃけどうでもいいのだが)