
- PDFのメタデータの文字化けの解消方法
- PDFのタイトルや作成者を
\title,\authorから自動的に設定する方法
を扱った。
今度は、PDFの目次(ブックマーク、しおりと呼ぶこともあるようだが、この記事では「目次」で通す)についてのTipsを扱う。
PDFの目次をつける
デフォルトでは、hyperrefパッケージを使うと自動的にPDFの目次がつく。 \tableofcontents で出力されるものと同じようなやつだ。これが文字化けする場合は、前回の記事を読んでほしい。
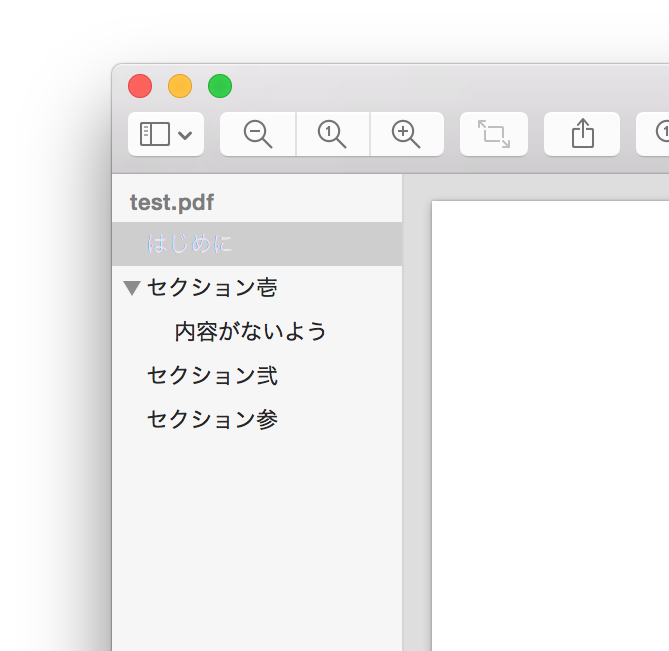
PDFの目次
なお、目次をつけるには (p/lua)latex を2回以上実行しなければならない。最初に実行したときに .out ファイルが生成され、2回目に実行した時にそれが反映される。1回目の実行で .aux ファイルに書き出す \label/\ref や、.toc ファイルに書き出す \tableofcontents と同じような感じだ。
目次にセクション番号をつける
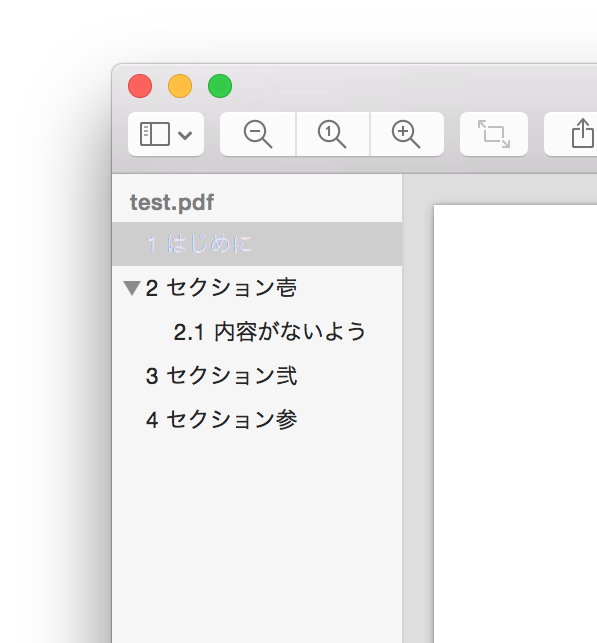
目次にセクション番号をつけた例
デフォルトでは、目次にはセクション等の番号がつかない。番号をつけるには、hyperrefの bookmarksnumbered オプションを指定する。
% 例1(platex+dvipdfmx の場合)
\documentclass[dvipdfmx]{jsarticle}
\usepackage[bookmarksnumbered]{hyperref}
\usepackage{pxjahyper}
略
% 例2(platex+dvipdfmx の場合。\hypersetup 使用)
\documentclass[dvipdfmx]{jsarticle}
\usepackage{hyperref}
\usepackage{pxjahyper}
\hypersetup{
bookmarksnumbered
}
略
% 例3(LuaTeX-ja + LaTeX の場合)
\documentclass{ltjsarticle}
\usepackage[unicode,bookmarksnumbered]{hyperref}
略
セクションのタイトルにTeX特有の表現を使っている場合
セクションのタイトルに、数式などのTeX特有の表現を使っていると、PDFの目次での表示が崩れる可能性がある。
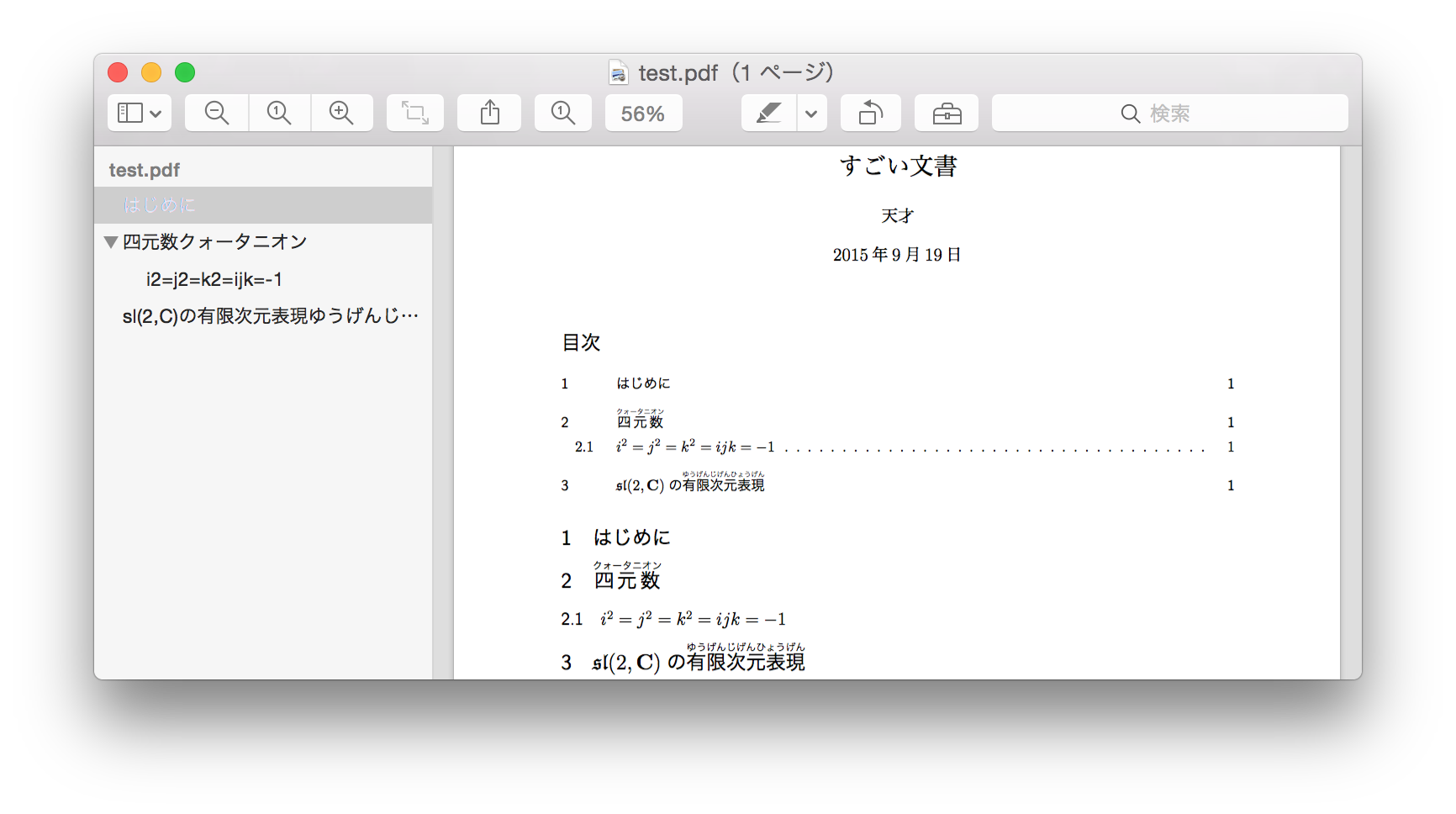
% 例4(platex+dvipdfmx の場合)
\documentclass[dvipdfmx]{jsarticle}
\usepackage{amssymb}
\usepackage{okumacro}
\usepackage{hyperref}
\usepackage{pxjahyper}
\title{すごい文書}
\author{天才}
\begin{document}
\maketitle
\tableofcontents
\section{はじめに}
\section{\ruby{四元数}{クォータニオン}}
\subsection{$i^2=j^2=k^2=ijk=-1$}
\section{$\mathfrak{sl}(2,\mathbf{C})$ の\ruby{有限次元表現}{ゆうげんじげんひょうげん}}
\end{document}
この例だと、PDF本文内での目次、セクションタイトルは意図した通りに表示されているが、PDFメタデータの目次(ブックマーク)では、 “四元数クォータニオン” “i2=j2=k2=ijk=-1” のように、ルビや添字の情報が落ちている。PDFメタデータはプレーンテキストだから、まあしょうがないと言えばそうなのだが、もうちょっと何とかならないのか。
そこで、セクションタイトルなどの本文とPDFメタデータの両方に使われる文字列に対して、(本文の中で使う)TeXのコードと、(メタデータで使う)プレーンテキストを別々に指定しよう。hyperrefパッケージはそのために \texorpdfstring マクロを提供している。
\texorpdfstring マクロは
\texorpdfstring{TeXでの表現}{プレーンテキスト(PDFメタデータ)での表現}のように使う。
例4をもとにして \texorpdfstring を使ってみよう。ただし、Unicodeにある上付きの2を扱うために pLaTeX ではなく upLaTeX を使う。Unicodeの上付き2は textcomp パッケージの \texttwosuperior マクロで使える。
% 例5(uplatex+dvipdfmx の場合)
\documentclass[uplatex,dvipdfmx]{jsarticle}
\usepackage{amssymb}
\usepackage{textcomp} % \texttwosuperior
\usepackage{okumacro}
\usepackage{hyperref}
\usepackage{pxjahyper}
\title{すごい文書}
\author{天才}
\begin{document}
\maketitle
\tableofcontents
\section{はじめに}
\section{
\texorpdfstring{%
\ruby{四元数}{クォータニオン}%
}{%
四元数%
}%
}
\subsection{
\texorpdfstring{%
$i^2=j^2=k^2=ijk=-1$%
}{%
i\texttwosuperior=j\texttwosuperior=k\texttwosuperior=ijk=-1%
}%
}
\section{%
\texorpdfstring{%
$\mathfrak{sl}(2,\mathbf{C})$%
}{%
sl(2,C)%
}
の%
\texorpdfstring{%
\ruby{有限次元表現}{ゆうげんじげんひょうげん}%
}{%
有限次元表現%
}%
}
\end{document}
% 例6(LuaTeX-ja の場合)
\documentclass{ltjsarticle}
\usepackage{amssymb}
\usepackage{textcomp} % \texttwosuperior
\usepackage{luatexja-ruby}
\usepackage[unicode]{hyperref}
\title{すごい文書}
\author{天才}
\begin{document}
\maketitle
\tableofcontents
\section{はじめに}
\section{
\texorpdfstring{%
\ruby{四元数}{クォータニオン}%
}{%
四元数%
}%
}
\subsection{
\texorpdfstring{%
$i^2=j^2=k^2=ijk=-1$%
}{%
i\texttwosuperior=j\texttwosuperior=k\texttwosuperior=ijk=-1%
}%
}
\section{%
\texorpdfstring{%
$\mathfrak{sl}(2,\mathbf{C})$%
}{%
sl(2,C)%
}
の%
\texorpdfstring{%
\ruby{有限次元表現}{ゆうげんじげんひょうげん}%
}{%
有限次元表現%
}%
}
\end{document}
ちなみに、\TeX や \LaTeX は、hyperref側でうまいこと処理してくれるので、自分で \texorpdfstring{\LaTeX}{LaTeX} みたいのを書かなくてもよい。
PDF用の文字列にUnicodeのコードポイントを直接指定する
上付きの2(U+00B2)は、textcompパッケージに \texttwosuperior というマクロがあってそれを使えばうまいこといったが、そういう対応するマクロがない場合は、Unicodeのその文字を直接指定しなければならない。
upLaTeX + dvipdfmx + PXjahyper の場合
otfパッケージの \UTF{XXXX} が使える。正確には、PXjahyperパッケージが \UTF を上書きしてうまいこと動作するようにしてくれる。\UTF{XXXX} じゃなくて \Ux{XXXX} でもよい。
試した感じでは、U+10000 以上のコードポイントの文字が文字化けする。
% 例7
\documentclass[uplatex,dvipdfmx]{jsarticle}
\usepackage{amssymb}
\usepackage{textcomp} % \texttwosuperior
\usepackage{otf} % \UTF
\usepackage{okumacro}
\usepackage{hyperref}
\usepackage{pxjahyper}
中略
\section{%
\texorpdfstring{%
$\mathfrak{sl}(2,\mathbf{C})$
}{%
sl(2,\UTF{2102})%
}
の有限次元表現
}
LuaLaTeX の場合
hyperrefパッケージの README によると、 ucs パッケージの \unichar がこの目的に使えるようである。試した限りでは \symbol やluatexja-otfパッケージの \UTF は使えない。
あるいは、直接その文字をソースに書いてもよさそうだ。
% 例8
\documentclass{ltjsarticle}
\usepackage{amssymb}
\usepackage{ucs} % \unichar
\usepackage[unicode]{hyperref}
\PrerenderUnicode{} % なんか必要っぽい
中略
\section{%
\texorpdfstring{%
$\mathfrak{sl}(2,\mathbf{C})$%
}{%
sl(2,\unichar{"2102})%
}
の有限次元表現%
}
または
\section{%
\texorpdfstring{%
$\mathfrak{sl}(2,\mathbf{C})$%
}{%
\unichar{"1D530}\unichar{"1D529}(2,\unichar{"1D402})%
}
の有限次元表現%
}
または
\section{%
\texorpdfstring{%
$\mathfrak{sl}(2,\mathbf{C})$%
}{%
𝔰𝔩(2,𝐂)%
}
の有限次元表現%
}
ピンバック: LaTeXでPDF出力する際のTips | 雑記帳
> 試した感じでは、U+10000 以上のコードポイントの文字が文字化けする。
\usepackage[bigcode]{pxjahyper}
のように、bigcodeオプションをつけると、(\UTF{…}の場合も直接文字を書く場合も)
U+10000以上の文字が正常に処理されるようになります。
ただしbigcodeを指定する場合は、「UTF8-UTF16」というCMapファイルがTeX環境に
インストールされている必要があります。
古い環境だと入っていないため、bigcodeをデフォルトにしていないのです。
>>デフォルトでは、目次にはセクション等の番号がつかない。番号をつけるには、hyperrefの bookmarksnumbered オプションを指定する。
この2行、このTipsが、ものすごく役に立ちました。
\usepackage[pdftex,bookmarksopen,bookmarksnumbered]{hyperref}
でコンパイルしたら、PDFのしおりが全部開いたままでオープンし、かつ、章・節番号もちゃんと(1, 2, 2.1, A, A.1…)付加されていました。完璧です。
日付を見たら、なんと5年7か月前の投稿……(゚д゚)!あまりにも遠い昔過ぎて、涙目になります。
しかし、今現在でも hyperref パッケージは、デフォルトで章・節番号を自動で付加してくれないので、このTipsは10年後も生き残ると思っています。どうもありがとうございます。