
先日、「新しくプログラミング言語を作る際に文字列型をどうするべきか」という記事に私の文字列型についての持論を書きました。
この記事では、私が作っているLunarMLというStandard ML処理系で文字列をどう扱っているか(あるいは、どう扱う予定であるか)を紹介します。
Standard MLでの文字列の扱い
Standard MLには標準の文字列型 string があり、これは8ビット文字列です。つまり、任意のバイト列を表現できます。エンコーディングについては何らかのASCII互換エンコーディングを採用することが期待されています。このほか、WideString.string というワイド文字列のための型がありますが、そこまで広く使われていないようです。
部分文字列を効率的に操作するための substring という型もあります。
SMLでUnicodeを扱う場合はUTF-8を使うのが自然な発想です。実際、UTF-8を扱うライブラリーがいくつか存在します。
- The UTF8 structure (smlnj-lib)
- diku-dk/sml-unicode: SML Unicode Library
- cannam/sml-utf8: UTF-8 encoder and decoder and simple wide-string type in Standard ML.
独自バイトコードやネイティブコードを出力する処理系ならそれで良いのですが、JVMやCLI、JavaScriptをターゲットとする処理系ではターゲット標準の文字列が16ビット文字列なので困ります。既存のSML処理系はどうしているかというと、MLj/SML.NETはSMLの文字列も16ビットとしているようです。SMLToJsは16ビット文字列に8ビット文字列を突っ込んでいるようです。
しかし、SMLの string 型の表すものがターゲットによって異なると、移植性のあるプログラムでUnicodeを扱うことが困難になります。条件コンパイルの仕組みがあれば手間はかかってもなんとかやっていけるかもしれませんが、SMLには条件コンパイルの仕組みがありません。「16ビット文字列に8ビット文字列を突っ込む」場合は、JavaScriptと相互運用した時にLatin-1以外の文字を扱えないことになります。
LunarMLでの文字列の扱い
LunarMLはLuaやJavaScriptなど、複数のターゲットにコンパイルできることを志向する処理系であり、「ターゲットによって文字列の扱いが異なる」という問題に真正面から立ち向かう必要があります。
考えられる方策はいくつかあって、
- ターゲットネイティブの文字列型を使い、エンコーディングの違いは条件コンパイルの仕組みを用意してどうにかしてもらう
string型は常に8ビット文字列とする。たとえターゲットがJavaScriptやJVM、CLIであっても
などが考えられます。LunarMLでは後者を選択しました。つまり、ターゲットがJavaScriptであっても8ビット文字列を使います。JavaScriptの文字列との混在をエラーとするため、8ビット文字列の表現にはJavaScriptの Uint8Array を使うことにしました。
とは言っても、JavaScriptと連携する上ではJavaScriptネイティブの文字列を扱える手段が必要です。Standard MLの文字列型は複数あっても良い(文字列リテラルのオーバーロードが考慮されている)ので、追加の文字列型 String16.string によってJavaScriptの文字列を表すことにしました。
Uint8Array に格納したUTF-8文字列とJavaScriptのUTF-16文字列は、WebやNode.jsで使える TextEncoder/TextDecoder というAPIで変換できます。
将来、仮にPythonやSchemeなどのUTF-32を使う言語にコンパイルできるようにする場合は、String32.string という文字列型を使うことになるでしょう。
string 型を全てのターゲットで提供するのは当然ですが、 String16.string や String32.string も全てのターゲットで提供します。JavaScriptでは String32.string は Int32Array で実装し、Luaでは String16.string や String32.string はUTF-16BE/UTF-32BEで実装します(辞書式順序の比較演算を使いまわせるようにBEを採用します)。
LunarMLでのUnicode文字列の扱い
前節をまとめると、LunarMLで使える文字列型は
string: 8ビット文字列(Unicodeを扱う場合はUTF-8を想定)String16.string: 16ビット文字列(UTF-16を想定)String32.string: 21ビット文字列(UTF-32を想定)
があります。しかし、「ターゲットにとって自然な形でUnicode文字列を扱いたい」という場合にはこれでは不足がありそうです。つまり、「JavaScript等では String16.string でUnicode文字列を表現し、他のターゲットでは string で表現する」というプログラムを自然に書けるようにするにはさらなる抽象化が必要になります。
そこで、LunarMLでは「Unicodeスカラー値の列」を表す抽象的な型 Unicode.ustring を用意することにしました。これはLuaバックエンドでは string 型の(不透明な)エイリアスであり、JavaScriptバックエンドでは String16.string のエイリアスとなります。さらに、不変条件として「正しいUnicode文字列であること(well-formedであること)」を課します。
ustring からは、各エンコーディングで具体的な文字列型に変換(エンコード)する関数を提供します。これらはどのターゲットでも利用できますが、実行時のコストはターゲットによって O(1) だったり O(n) だったりします。
Unicode.UTF8.encode : ustring -> string
Unicode.UTF16.encode : ustring -> String16.string
Unicode.UTF32.encode : ustring -> String32.string具体的な文字列型から変換(デコード)する関数も用意します。不正な文字列があった場合はデフォルトではU+FFFDに置き換えますが、検査して option で返すバージョンも用意します。
Unicode.UTF8.decode : string -> ustring
Unicode.UTF8.validate : string -> ustring option
Unicode.UTF16.decode : String16.string -> ustring
Unicode.UTF16.validate : String16.string -> ustring option
Unicode.UTF32.decode : String32.string -> ustring
Unicode.UTF32.validate : String32.string -> ustring optionこのほか、1文字ずつデコードするイテレーター的な関数も用意します。usubstring は ustring のスライスに対応する型で、uchar はUnicodeスカラー値を表す型です。
Unicode.Substring.getc : usubstring -> (uchar * usubstring) option (* 型の不変条件で正当性が保証されているのでエラー処理は不要 *)
Unicode.UTF8.decode1Replace : substring -> (uchar * substring) option (* エラー時にはU+FFFDを返す *)
Unicode.UTF8.decode1Raise : substring -> (uchar * substring) option (* エラー時には例外を飛ばす *)
Unicode.UTF16.decode1Replace : Substring16.substring -> (uchar * Substring16.substring) option
Unicode.UTF16.decode1Raise : Substring16.substring -> (uchar * Substring16.substring) option
Unicode.UTF32.decode1Replace : Substring32.substring -> (uchar * Substring32.substring) option
Unicode.UTF32.decode1Raise : Substring32.substring -> (uchar * Substring32.substring) option用途によっては、実際に使われているエンコーディングによって処理を切り替えたいこともあるかもしれません。また、スライスの範囲をコードユニット単位で取得したいかもしれません。そこで、エンコーディングとスライスの内部表現にアクセスできるインターフェースも用意しています:
datatype Unicode.String.representation =
UTF8 of { uncheckedDecodeSubstring : substring -> usubstring, encodeSubstring : usubstring -> substring }
| UTF16 of { uncheckedDecodeSubstring : Substring16.substring -> usubstring, encodeSubstring : usubstring -> Substring16.substring }
| UTF32 of { uncheckedDecodeSubstring : String32.substring -> usubstring, encodeSubstring : usubstring -> String32.substring }
val Unicode.String.representation : Unicode.String.representationただ、このインターフェースだと文字列の出自に応じて複数の内部表現を使い分けたいという場合に向かないかもしれません。
これらのインターフェースがどの程度実用的かはこれから使ってみて判断しなければなりませんが、「ターゲットによって文字列型が違う」という問題に対して悪くない解を提供できたのではないかと思います。
ASCII文字列型もあると良いのでは
LunarMLはLuaやJavaScriptのソースコードを出力する言語です。そうすると、コンパイル後のコード長も気になってきます。
JavaScriptで Uint8Array を使って8ビット文字列を表現する場合は Uint8Array.of を使って文字列リテラルを表現することになるので、次のコードが
val a : String16.string = "Hello";
val b : string = "Hello";このようになります:
let a = "Hello";
let b = Uint8Array.of(72, 101, 108, 108, 111);Uint8Array.of を使ったコンパイル方法は出力コードの長さ的に不利です(圧縮をかけた場合にどうなるかは分かりませんが)。まあ、この場合は文字列リテラルのコンパイル方法を工夫すれば良いでしょう。つまり、
function utf8(s) {
return new TextEncoder().encode(s);
}というような補助関数を用意すれば
let b = utf8("Hello");と書けます。
UTF-8ならこれで良いかもしれませんが、「Unicodeのような大きなデータベースをバイト列として埋め込みたい」という場合には TextEncoder は使えませんし、Uint8Array.of を使うとコードの長さ的に不利なことが予想されます。コンパイラー側またはバイト列を埋め込む側でBase64エンコードするのが適当でしょう。
Base64のデコードをライブラリー側でやるとして、Base64をデコードする関数はどのような型を持つべきでしょうか。標準の文字列型 string
val Base64.decode : string -> Word8Vector.vectorだと Base64.decode "AAAA" のコンパイル結果に utf8 関数の呼び出しが挟まることになります。一方、
val Base64.decode : String16.string -> Word8Vector.vectorだとJavaScriptでは良くてもLuaでのコンパイル結果があまりよろしくなりません。
そこで、「ASCII文字列を表す型 String7.string」を追加して、ターゲットに適した表現を採用できると良いのでは、と思っています。これを使うと Base64.decode は
val Base64.decode : String7.string -> Word8Vector.vectorと書けます。
別の問題意識もあります。JavaScriptで整数を文字列化する場合に .toString() でまず得られるのはSMLで言う String16.string 型であり、 string 型を得るにはエンコードが必要になります。しかし、整数の文字列化結果はASCIIなので、ある種の文字列操作はASCIIだけで済む可能性があります。そういう場合にASCII文字列の型があれば、ターゲットに適した文字列で操作が完結するかもしれません。
そういうわけで、ASCII文字列の型 String7.string も追加しようかと思っています。これはそんなに広く使うことを想定するわけではありませんが。
まとめ
「ターゲットごとに異なる文字列型を最大限に活用しよう」という目標の下では、LunarMLでは次の5つの文字列型を提供するのがよさそうということになります:
string(String.string)String16.stringString32.stringUnicode.ustringString7.string
このうち3つが、ターゲットにおける自然な文字列型に対応します。Luaなら string, Unicode.ustring, String7.string の3つ、JavaScriptなら String16.string, Unicode.ustring, String7.string という具合です。
これらの文字列型の、意味を保ちつつエラーなしで変換できる方向は次のようになります:
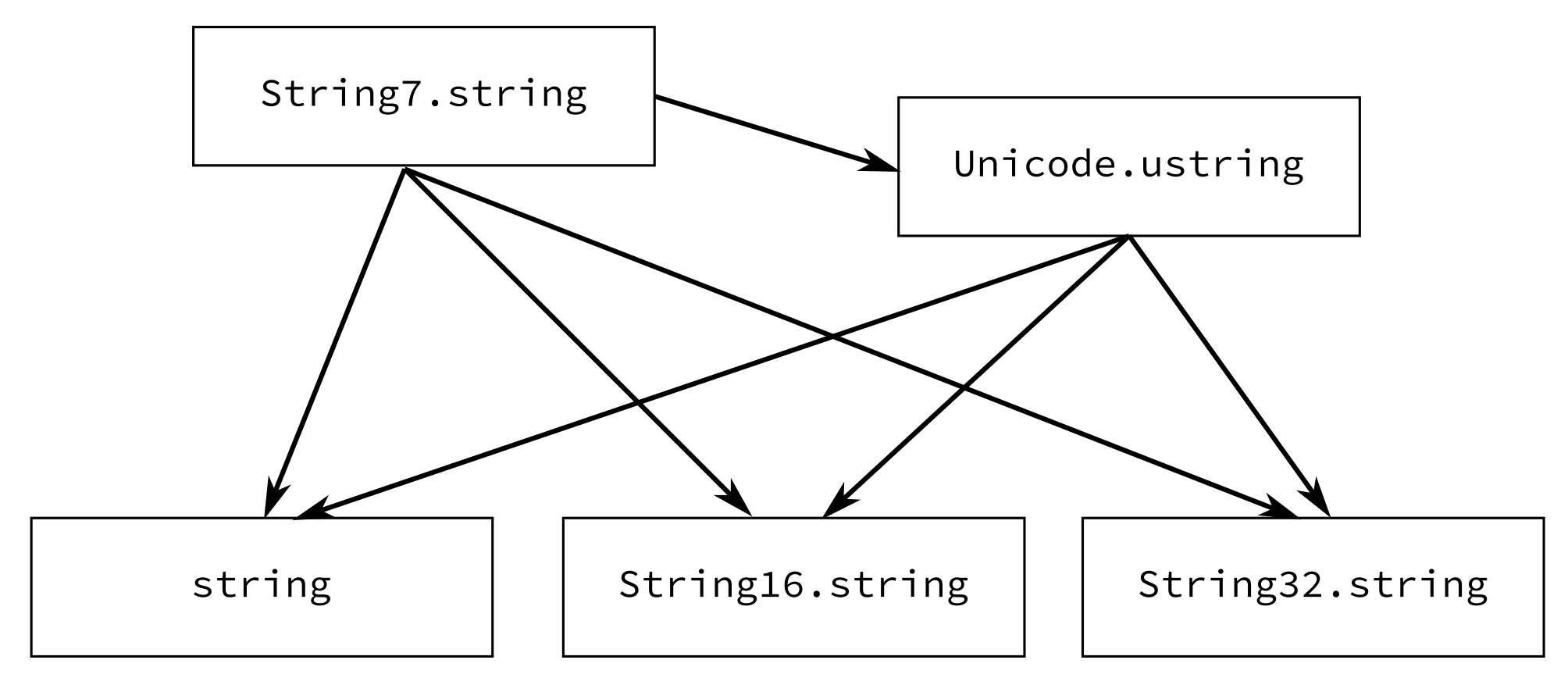
Standard MLにはワイド文字列 WideString.string の規定もあり、LunarMLでもこれを提供していますが、これはUnicode時代には使いづらいのでいずれ削除しようと思っています。
文字列型が5つもあると取っ付きづらいと思われるかもしれません。基本は8ビット文字列 string を使ってもらって、コンパイラーやライブラリーが内部的に他の文字列型を使う、という形にできるとよさそうです。